When I switched to Linux from Windows (which was not rally an option for me since my company is a window-less one :) ), i was missing some of the fancy free tools which ran only in Windows. I thought there must be someone out there who came up with a way to run windows compatible software in Linux machines. I was Googling to find a solution and came across WINE.(http://www.winehq.org/)
WINE stands for "WINE Is Not an Emulator." An emulator is a piece of software that makes one computer act like another. A company named Connectix, for instance, sells an emulator that lets a Macintosh behave like a Windows PC so anyone can use their Windows software on the Mac. Emulators, however, are pretty slow because they're constantly translating information on the fly.
The WINE project is an ambitious attempt to knock out one of the most important structural elements of the Microsoft monopoly.
It tries to clone what is known as the Win32 API, a panoply of features that make it easier to write software for a Microsoft machine.
It has produced some dramatic accomplishments making it possible to run major programs like Microsoft Word or Microsoft Excel on a Linux box without using Windows.
Saturday, December 29, 2012
Friday, December 28, 2012
Eclipse Plugins : MaintainJ
MaintainJ (http://www.maintainj.com/)
is a tool that can be used to generate sequence digrams when you run
the application. It's a great reverse engineering tool, but
unfortunaly most of the options are not available in the free
version. They allow a 7 day free trial of the full product, but I
just used what is available for free.
My application is deployed in WebLogic
and in order to use MaintainJ following things had to be done.
(Official user guide
http://www.maintainj.com/userGuide.jsp?param=install)
Step A: Install MaintainJ in WebLogic
Download MaintainJ.war from
http://www.maintainj.com/updates/4.0.0/MaintainJ.war
and deploy it in WebLogic
Once installed you can access the
following console.

There is a very clear step by step demo
here.
Step 1 and 2 are straightforward. In
step 2 we need to give the package names that need to be
instrumented.
Step 3 advised to start WebLogic using
following wrapper script.
/.../Oracle/Middleware/user_projects/domains/commercerouter-domain/bin/startWebLogic_with_mnj.sh
Since my application had a custom ant
target that starts WebLogic through it, I added what is there in the
above script to my ant target as shown below.
<classpath>
...
<pathelement location="${bea.home}/user_projects/domains/commercerouter-domain/maintainj"/>
<pathelement location="${bea.home}/user_projects/domains/commercerouter-domain/maintainj/MaintainJAspect.jar"/>
</classpath>
...
<jvmarg value="-javaagent:${bea.home}/user_projects/domains/commercerouter-domain/maintainj/aspectjweaver.jar" />
</wlserver>
It's possible to add multiple
javaagents. So no need to worry if it's already defined pointing to
another jar.
Running my ant target started WebLogic
and Step 4 in Wizard showd everything is fine.
Step 5 started call trace.
Ran a test case and stopped the trace.
Trace files were generated.
Step B: Install MaintainJ plugin in Eclipse to view the trace files.
Installed plugin from update site
http://www.maintainj.com/updates/4.0.0
Created a new MaintainJ project in
eclipse and copy the trace files to it.
Diagrams were displayed as shown below.

Monday, December 24, 2012
Oracle 10g Express
Oracle Database Express Edition (Oracle Database XE) is an entry-level, small-footprint database which is free to develop, deploy, and distribute.
[bash]$ rpm -hiv oracle-xe-univ-10.2.0.1-1.0.i386.rpm
Ubuntu
[bash]$ sudo dpkg -i oracle-xe-universal_10.2.0.1-1.0_i386.deb
Specify the HTTP port that will be used for Oracle Application Express [8080]:8000
Specify a port that will be used for the database listener [1521]:
Specify a password to be used for database accounts. Note that the same
password will be used for SYS and SYSTEM. Oracle recommends the use of
different passwords for each database account. This can be done after
initial configuration:
Confirm the password:
Do you want Oracle Database 10g Express Edition to be started on boot (y/n) [y]: y
/etc/default/oracle-xe
#This is a configuration file for automatic starting of the Oracle
#Database and listener at system startup.It is generated By running
#'/etc/init.d/oracle-xe configure'.Please use that method to modify this
#file
# ORACLE_DBENABLED:'true' means to load the Database at system boot.
ORACLE_DBENABLED=true
# LISTENER_PORT: Database listener
LISTENER_PORT=1521
# HTTP_PORT : HTTP port for Oracle Application Express
HTTP_PORT=8080
# Configuration : Check whether configure has been done or not
CONFIGURE_RUN=true
[bash]$ sudo /sbin/service oracle-xe start
[bash]$ sudo /sbin/service oracle-xe stop
[bash]$ sudo /sbin/service oracle-xe status
Ubuntu
[bash]$ sudo service oracle-xe start
[bash]$ sudo service oracle-xe stop
[bash]$ sudo service oracle-xe status
or
[bash]$ sudo /etc/init.d/oracle-xe start
[bash]$ sudo /etc/init.d/oracle-xe stop
sudo /etc/init.d/oracle-xe stop
Cent-OS
[bash]$ rpm -e oracle-xe-univ-10.2.0.1-1.0
Ubuntu
[bash]$ sudo dpkg -r oracle-xe-universal
Above doesn't remove everything
Use following
[bash]$ sudo apt-get remove --purge oracle-xe-universal
It removes following folders as well.
/usr/lib/oracle
/etc/init.d/oracle-xe
/etc/default/oracle-xe
On the client side, the Oracle Net foundation layer receives client application requests and resolves all generic computer-level connectivity issues, such as:
On the server side, the Oracle Net foundation layer performs the same tasks as it does on the client side and also works with the listener to receive incoming connection requests.
The database server receives an initial connection from a client application through the listener. The listener is an application positioned on top of the Oracle Net foundation layer
The listener brokers client requests, handing off the requests to the Oracle database server. Every time a client requests a network session with a database server, a listener receives the initial request.
Each listener is configured with one or more protocol addresses that specify its listening endpoints. Clients configured with one of these protocol addresses can send connection requests to the listener.
Once a client request has reached the listener, the listener selects an appropriate service handler to service the client's request and forwards the client's request to it. The listener determines if a database service and its service handlers are available through service registration. During service registration, the PMON process—an instance background process—provides the listener with information about the following:
# listener.ora Network Configuration File:SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(SID_NAME = PLSExtProc)
(ORACLE_HOME = /usr/lib/oracle/xe/app/oracle/product/10.2.0/server)
(PROGRAM = extproc)
)
)
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC_FOR_XE))
(ADDRESS = (PROTOCOL = TCP)(HOST = dev30)(PORT = 1521))
)
)
DEFAULT_SERVICE_LISTENER = (XE)
A net service name is an alias mapped to a database network address contained in a connect descriptor. A connect descriptor contains the location of the listener through a protocol address and the service name of the database to which to connect. Clients and database servers (that are clients of other database servers) use the net service name when making a connection with an application.
ORACLE_HOME/network/admin/tnsnames.ora
# tnsnames.ora Network Configuration File:XE =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = dev30)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = XE)
)
)
EXTPROC_CONNECTION_DATA =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC_FOR_XE))
)
(CONNECT_DATA =
(SID = PLSExtProc)
(PRESENTATION = RO)
)
)
[bash] $ tnsping xe
TNS Ping Utility for Linux: Version 10.2.0.1.0 - Production on 24-DEC-2012 14:54:26
Copyright (c) 1997, 2005, Oracle. All rights reserved.
Used parameter files:
Used TNSNAMES adapter to resolve the alias
Attempting to contact (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = cnb18)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = XE)))
OK (0 msec)
java.sql.SQLException: Io exception: The Network Adapter could not establish the connection
I recived the above due to adding the wrong port when configuring. Eventhough it was reconfigured and everything looked fine in config files stil I got the following error.
ORA-12505: TNS:listener does not currently know of SID given in connect descriptor
Uninstalling didn't solve the problem. Finally deleting /usr/lib/oracle/xe and reinstall worked!!
I recived the following error
[WLServer adminserver] ORA-12519, TNS:no appropriate service handler found
And increasing the number of processes by running the following query as the admin user solved it.
ALTER SYSTEM SET PROCESSES=200 SCOPE=SPFILE; ALTER SYSTEM SET;
Install
Cent-OS[bash]$ rpm -hiv oracle-xe-univ-10.2.0.1-1.0.i386.rpm
Ubuntu
[bash]$ sudo dpkg -i oracle-xe-universal_10.2.0.1-1.0_i386.deb
Configure
[bash]$ sudo /etc/init.d/oracle-xe configureSpecify the HTTP port that will be used for Oracle Application Express [8080]:8000
Specify a port that will be used for the database listener [1521]:
Specify a password to be used for database accounts. Note that the same
password will be used for SYS and SYSTEM. Oracle recommends the use of
different passwords for each database account. This can be done after
initial configuration:
Confirm the password:
Do you want Oracle Database 10g Express Edition to be started on boot (y/n) [y]: y
/etc/default/oracle-xe
#This is a configuration file for automatic starting of the Oracle
#Database and listener at system startup.It is generated By running
#'/etc/init.d/oracle-xe configure'.Please use that method to modify this
#file
# ORACLE_DBENABLED:'true' means to load the Database at system boot.
ORACLE_DBENABLED=true
# LISTENER_PORT: Database listener
LISTENER_PORT=1521
# HTTP_PORT : HTTP port for Oracle Application Express
HTTP_PORT=8080
# Configuration : Check whether configure has been done or not
CONFIGURE_RUN=true
Start/stop/check the status of oracle
Cent-OS[bash]$ sudo /sbin/service oracle-xe start
[bash]$ sudo /sbin/service oracle-xe stop
[bash]$ sudo /sbin/service oracle-xe status
Ubuntu
[bash]$ sudo service oracle-xe start
[bash]$ sudo service oracle-xe stop
[bash]$ sudo service oracle-xe status
or
[bash]$ sudo /etc/init.d/oracle-xe start
[bash]$ sudo /etc/init.d/oracle-xe stop
Browse the Oracle service
http://localhost:8000/apex/Uninstall
Stop serversudo /etc/init.d/oracle-xe stop
Cent-OS
[bash]$ rpm -e oracle-xe-univ-10.2.0.1-1.0
Ubuntu
[bash]$ sudo dpkg -r oracle-xe-universal
Above doesn't remove everything
Use following
[bash]$ sudo apt-get remove --purge oracle-xe-universal
It removes following folders as well.
/usr/lib/oracle
/etc/init.d/oracle-xe
/etc/default/oracle-xe
Listeners
The Oracle Net foundation layer is responsible for establishing and maintaining the connection between the client application and database server, as well as exchanging messages between them. The Oracle Net foundation layer is able to perform these tasks because of a technology called Transparent Network Substrate (TNS). TNS provides a single, common interface for all industry-standard protocols. In other words, TNS enables peer-to-peer application connectivity, where two or more computers can communicate with each other directly, without the need for any intermediary devices.On the client side, the Oracle Net foundation layer receives client application requests and resolves all generic computer-level connectivity issues, such as:
- The location of the database server or destination
- How many protocols are involved in the connection
- How to handle interrupts between client and database server based on the capabilities of each
On the server side, the Oracle Net foundation layer performs the same tasks as it does on the client side and also works with the listener to receive incoming connection requests.
The database server receives an initial connection from a client application through the listener. The listener is an application positioned on top of the Oracle Net foundation layer
The listener brokers client requests, handing off the requests to the Oracle database server. Every time a client requests a network session with a database server, a listener receives the initial request.
Each listener is configured with one or more protocol addresses that specify its listening endpoints. Clients configured with one of these protocol addresses can send connection requests to the listener.
Once a client request has reached the listener, the listener selects an appropriate service handler to service the client's request and forwards the client's request to it. The listener determines if a database service and its service handlers are available through service registration. During service registration, the PMON process—an instance background process—provides the listener with information about the following:
- Names of the database services provided by the database
- Name of the instance associated with the services and its current and maximum load
- Service handlers (dispatchers and dedicated servers) available for the instance, including their type, protocol addresses, and current and maximum load
Listener Parameters (listener.ora)
Listener configuration, stored in the listener.ora file, consists of the following elements:- Name of the listener
- Protocol addresses that the listener is accepting connection requests on
- Database services
- Control parameters
# listener.ora Network Configuration File:SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(SID_NAME = PLSExtProc)
(ORACLE_HOME = /usr/lib/oracle/xe/app/oracle/product/10.2.0/server)
(PROGRAM = extproc)
)
)
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC_FOR_XE))
(ADDRESS = (PROTOCOL = TCP)(HOST = dev30)(PORT = 1521))
)
)
DEFAULT_SERVICE_LISTENER = (XE)
Local Naming Parameters (tnsnames.ora)
This tnsnames.ora file is a configuration file that contains net service names mapped to connect descriptors for the local naming method, or net service names mapped to listener protocol addresses.A net service name is an alias mapped to a database network address contained in a connect descriptor. A connect descriptor contains the location of the listener through a protocol address and the service name of the database to which to connect. Clients and database servers (that are clients of other database servers) use the net service name when making a connection with an application.
ORACLE_HOME/network/admin/tnsnames.ora
# tnsnames.ora Network Configuration File:XE =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = dev30)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = XE)
)
)
EXTPROC_CONNECTION_DATA =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC_FOR_XE))
)
(CONNECT_DATA =
(SID = PLSExtProc)
(PRESENTATION = RO)
)
)
Troubleshooting
[bash] $ tnsping xe
TNS Ping Utility for Linux: Version 10.2.0.1.0 - Production on 24-DEC-2012 14:54:26
Copyright (c) 1997, 2005, Oracle. All rights reserved.
Used parameter files:
Used TNSNAMES adapter to resolve the alias
Attempting to contact (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = cnb18)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = XE)))
OK (0 msec)
java.sql.SQLException: Io exception: The Network Adapter could not establish the connection
I recived the above due to adding the wrong port when configuring. Eventhough it was reconfigured and everything looked fine in config files stil I got the following error.
ORA-12505: TNS:listener does not currently know of SID given in connect descriptor
Uninstalling didn't solve the problem. Finally deleting /usr/lib/oracle/xe and reinstall worked!!
I recived the following error
And increasing the number of processes by running the following query as the admin user solved it.
ALTER SYSTEM SET PROCESSES=200 SCOPE=SPFILE; ALTER SYSTEM SET;
Sunday, December 23, 2012

Saturday, December 22, 2012
Using Java’s reflection for testing private methods

Groovy is the dynamic language syntax for Java. As such, it can interact pretty seamlessly with
Java code (including compiled byte code), allowing you much more flexible syntax. You can invoke the standard reflection mechanism in Java using the Groovy syntax as shown below.

Ship Vasa
In 1625, King Gustav II Adolf of Sweden commissioned the finest
warship ever built. He hired the best ship builder, grew a special forest of
the mightiest oaks, and started work on the ship Vasa.
The king kept making requests to make the ship grander and
grander, with ornate decorations everywhere. At some point, he decided that he
wanted a ship with two gun decks, unlike any in the world. His ship was going
to be the most powerful in the ocean. And he needed it right away because of a
diplomatic issue that was popping up.
Of course, the ship builder had designed the ship with only
one gun deck in mind, but because the king asked for it, he got his extra gun
deck. Because they were in a rush, the builders didn’t have time for “lurch”
tests, where a group of sailors would run from one side to the other to make
sure the ship didn’t rock too much (in other words, wasn’t too top heavy).
On the inaugural voyage, the Vasa sank within a few hours.
While adding all the “features” to the ship, they managed to make it
unseaworthy. The Vasa sat at the bottom of the North Sea until early in the
20th century, when the well-preserved ship was raised and placed in a museum.
And here is the interesting question: whose fault was the
sinking of the Vasa? The king, for asking for more and more features? Or the
builders, who built what he wanted without vocalizing their concerns loudly
enough? Look around at the project on which you are currently working: are you creating
another Vasa?
Little things that can make you a productive programmer
- Launchers that allow you to type the first part of the name of an application (or document) to launch it.
- VI editor that allows mouseless editing.
- Auto completion
- Clipboads. Allows to copy multiple things before pasting begins. Prevents context switching
- History in command line
- IDE shortcuts
- Most used icons on the top of screen
- Switch off email notifications
- Have an official quite time at office
- Search over navigation
- Know find commands
- Rooted views
- Multiple monitors
- Virtual desktops
-The Productive Programmer by Neal Ford
What can Galileo teach a software engineer?
One of the great rebels of history was Galileo, who apparently
didn’t believe anything that anyone told him. He always had to try it for
himself. The accepted wisdom before his time maintained that a heavier object
would fall faster than a lighter one. This was based on Aristotelian thinking,
where thinking hard about something logically had more merit than
experimenting. Galileo didn’t buy it, so he went to the top of the Leaning
Tower of Pisa and dropped rocks. And fired rocks from cannons. And discovered that,
nonintuitively, all objects fall at the same rate (if you discount air
resistance).
What Galileo did was prove that things that seem
nonintuitive can in fact be true, which is a valuable lesson. Some hard-fought
knowledge about software development is not intuitive. The idea that you can
design the entire software up front, and then just transcribe it seems logical,
but it doesn’t work in the real world of constant change.
-The Productive Programmer by Neal Ford
-The Productive Programmer by Neal Ford
Friday, December 21, 2012
Eclipse Versions
| Codename | Date | Platform version | |
|---|---|---|---|
| N/A | 2004 | 3.0 | |
| N/A | 2005 | 3.1 | |
| Callisto | 2006 | 3.2 | |
| Europa | 2007 | 3.3 | |
| Ganymede | 2008 | 3.4 | |
| Galileo | 2009 | 3.5 | |
| Helios | 2010 | 3.6 | |
| Indigo | 2011 | 3.7 | |
| Juno | 2012 | 4.2 | |
| Kepler | 2013 (planned) | 4.3 |
Legend:
Old version
Older version, still supported
Latest
version
Latest preview version
Future
release
Wednesday, September 5, 2012




Monday, September 3, 2012
Eclipse Configurations
Eclipse startup is controlled by the options in $ECLIPSE_HOME/eclipse.ini. If $ECLIPSE_HOME is not defined, the default eclipse.ini in your Eclipse installation directory is used.
eclipse.ini is a text file containing command-line options that are added to the command line used when Eclipse is started up
All lines after -vmargs are passed as arguments to the JVM, so all arguments and options for eclipse must be specified before -vmargs (just like when you use arguments on the command-line)
For more infor: http://wiki.eclipse.org/Eclipse.ini
More Options: http://help.eclipse.org/indigo/index.jsp?topic=/org.eclipse.platform.doc.isv/reference/misc/runtime-options.html
Optimal Settings: http://stackoverflow.com/questions/142357/what-are-the-best-jvm-settings-for-eclipse
My current settings (Eclipse Helios running in CentOS)
-vm
/opt/jdk1.5.0_15/bin/java
-startup
plugins/org.eclipse.equinox.launcher_1.1.0.v20100507.jar
--launcher.library
plugins/org.eclipse.equinox.launcher.gtk.linux.x86_1.1.1.R36x_v20100810
-showsplash
org.eclipse.platform
--launcher.XXMaxPermSize
256m
--launcher.defaultAction
openFile
-vmargs
-Xms1024m
-Xmx2096m
-XX:MaxPermSize=256m
-Dorg.eclipse.swt.browser.UseWebKitGTK=true
eclipse.ini is a text file containing command-line options that are added to the command line used when Eclipse is started up
All lines after -vmargs are passed as arguments to the JVM, so all arguments and options for eclipse must be specified before -vmargs (just like when you use arguments on the command-line)
| -vm |
locate the Java VM to use to run Eclipse. It should be the full file system path to an appropriate: Java jre/bin directory, Java Executable, Java shared library (jvm.dll or libjvm.so), or a Java VM Execution Environment description file. |
| -startup |
The location of jar used to startup eclipse. The jar referred to should have the Main-Class attribute set to org.eclipse.equinox.launcher.Main. |
| --launcher.library |
the location of the eclipse executable's companion shared library. |
| -showSplash |
specifies the bitmap to use in the splash screen. |
| --launcher.XXMaxPermSize |
If specified, and the executable detects that the VM being used is a Sun VM, then the launcher will automatically add the -XX:MaxPermSize= |
| --launcher.defaultAction | specifies the default action to take when the launcher is started without any "-" arguments on the command line. |
| -vmargs [vmargs*] (Executable, Main) | Used to customize the operation of the Java VM to use to run Eclipse. |
For more infor: http://wiki.eclipse.org/Eclipse.ini
More Options: http://help.eclipse.org/indigo/index.jsp?topic=/org.eclipse.platform.doc.isv/reference/misc/runtime-options.html
Optimal Settings: http://stackoverflow.com/questions/142357/what-are-the-best-jvm-settings-for-eclipse
My current settings (Eclipse Helios running in CentOS)
-vm
/opt/jdk1.5.0_15/bin/java
-startup
plugins/org.eclipse.equinox.launcher_1.1.0.v20100507.jar
--launcher.library
plugins/org.eclipse.equinox.launcher.gtk.linux.x86_1.1.1.R36x_v20100810
-showsplash
org.eclipse.platform
--launcher.XXMaxPermSize
256m
--launcher.defaultAction
openFile
-vmargs
-Xms1024m
-Xmx2096m
-XX:MaxPermSize=256m
-Dorg.eclipse.swt.browser.UseWebKitGTK=true
Eclipse Plugins : ObjectAid UML Explorer
If you are a Eclipse user and you want to construct a class diagram from an existing codebase, you can use the following.
Simply go Help ==> Install New Software
Add http://www.objectaid.com/update as a site and it will find the tool.
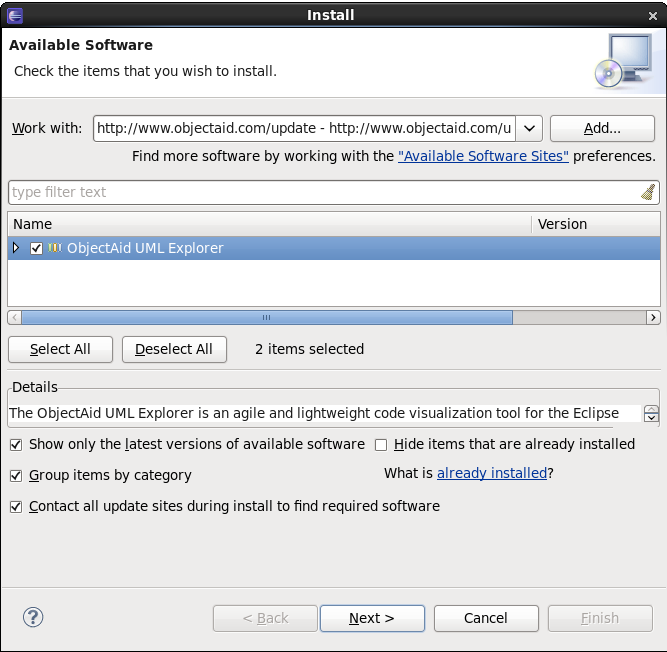
You need a license to use the Sequence Diagram Editor, but the class diagrams are free. It's extremely easy to use and a must-have in your eclipse toolbox.

Visit http://www.objectaid.com/ for more infor.
Eclipse Crashing Issue
My eclipse kept on crashing in my CentOS PC. Issue seemed to be related to having firefox as the default browser. But changing the default browser was not possible since it was crashing every time I tried to change it. Tried out several versions of eclipse with no luck.
Following solution was found from a blog and it worked!
Add the following to eclipse.ini.
-Dorg.eclipse.swt.browser.UseWebKitGTK=true
Following solution was found from a blog and it worked!
Add the following to eclipse.ini.
-Dorg.eclipse.swt.browser.UseWebKitGTK=true
Wednesday, August 22, 2012
Are you ready yet?
We had the privilege of participating
in Are You Ready? 2012 organized by the Rotaract Club of University
of Moratuwa. (http://www.areyouready.uom.lk/)
It was a huge success because we were able to find some great people
who fit in to our requirements.
I thought I should write a few points
here that might be useful to the fresh graduates
Being from UOM myself, and associated
with many mora graduates at different levels in the cooperate world,
I have no doubt about the capabilities and competencies of UOM
products. Yet it's sad to see some candidates perform poorly at
interviews merely because they haven't paid any attention to some
simple facts.
Interviews need practice. Make sure
that your first interview is not with the actual place you want to
join. The opportunities to participate in interviews are so many and
they are FREE! Career days are wonderful for you to get this learning
experience.
Specially in a career day like this, we
don't get to read your CV word by word. Even at office this is
usually the case. People have better things to do than reading
hundreds of boring Cvs. We'd usually scan through. We'd pay attention
to some areas, like projects and internship. Be mindful of that when
you prepare the CV. Highlight only the important points and keep the
CV short and sweet.
If there's one good advice that can be
given to a fresh candidates, it's to think like an interviewer. See
yourself in the other chair and imagine you're listening to the
answers. It can make a world of difference to the way you present
yourself.
The first thing you get to speak about
in at least 95% of the interviews is describing yourself. This is not
your grade 3 English class period where you get to speak 2 minutes
about “Myself” No! But it's hard to believe how many people
actually go on “I'm Sunil Gamage, I'm from Panadura. My father is a
government officer, my mother is a housewife, I have 2 brothers and 1
sister .... bluh bluh bluh” and sometimes if we don't intertwine
and stop they'd go on describing pets, hobbies and what their
neighbors look like!
Remember, we're interested in hiring
YOU! Not your parents or your siblings and it doesn't matter if your
father is a farmer, a government or the president. It doesn't matter
from where in the island you're coming from.
Here is your opportunity to paint the
image about yourself as you want it in the mind of the interviewer,
your opportunity to show what a great hire you can be, how confident
you are and how passionate you are about work.
These few golden minutes are just too
important to waste.
Next, since you don't have work
experience yet, there are few things any interviewer will ask about.
- The final year project
- Other projects
- Internship period
All interviewers, specially those who
represent IT companies, love to see a lot of projects in your CV.
Specially the ones that you did outside the mandatory requirements of
your degree. One candidate who had a poor GPA etc, made it to the
next level simply because of the Google Summer of Code projects he
did out of his own interest.
You may make a few grammar mistakes, a
few pronunciation mistakes and that's ok. We do not, i repeat, do not
hire you for your English language proficiency, but we DO hire you
for your communication skills. What is the difference? When you work
in a company you do not work alone, you have to deal with people at
different levels. It's important that you're able to convey an idea,
a message, clearly and effectively. When you talk about your
projects, if we understand, that means you have communicated well.
But if you have left us scratching our heads and wondering what you
have done, that means you haven't communicated well. Can you
communicate well in broken English? Sure you do!
No company has employees only from UOM
and only those who have got 3As for their A/L. That means we get Cvs
of people with different levels of qualifications. Among them, your
CV is sure to shine. You already have a lot at your side. So why be
nervous? Be confident, take a deep breath and feel good about
yourself. Don't let some questions, to which you don't know the
answer, make you feel stupid. Nobody in the world knows everything
about even a single subject. If you don't know, fine, admit it and
may be try to make an intelligent guess and tell that it's guess. Do
not expect interviewers to feel confident about you, if you are not
showing any confidence yourself.
Chances are that you are smarter than
your interviewers, just like back in school you were smarter than
most of your teachers. You were smarter but your teachers taught you.
Why? For the simple reason that they knew better about the subject
than you did. So is the case with interviews, they know better about
the industry, the company and the requirements they have. Be smart
and confident but don't be arrogant and give airs to your
interviewers. Nobody wants to work with people who believe they are
know-alls.
Finally, Google and find some articles
and books on facing interviews. At least spend the time you'd spend
on an assignment to prepare for your interviews. Think about it. You
may get a few extra marks for the assignment and forget about it, but
an interview will determine what you do and how much you get in terms
of experience and of-course money for at least a few years.
Isn't it much more critical?
Monday, August 13, 2012
SVN Repository Migration
The back up process was taking around 6 hours and a senior manager was threatening to get rid of all the history and to export the content to a new repository.
Now as software engineers we know it's not a very good thing to do. How many times do we take our shovels and put on our overalls and dig deep into the mystic history of svn in search of skeletons and criminals. No we NEED that history!
I, the poor little new joinee who never had anything to do with any kind of repository maintenance, was given the mammoth task of finding a solution, and finding it quick. Break that big evil repo into pieces I was told.
What kind of hammers can I use for this? As the first step I downloaded the svn book 1.7, a document freely available on internet which is compiled by the svn crew. And to put a long story short, here are the options I considered; in a nutshell.
Investigated Options
Copy & Delete
Why not copy the entire repository and delete unwanted projects along with their history. That should be simple enough. There is a little problem though. SVN doesn't provide an option to delete a part of repository with history. You simply can't get rid of your past in svn. If you really really want to do it, svn makes you work real hard for it. Well... Isn't there a command called svn delete? Yes but it will only mark the files as deleted but it retains everything and in fact will increase the repo size. Conclusion: Cannot be used.
svn export
This command is used to export a clean directory tree with no history and no meta data. (those pesky little .svn files that like to hide) Not a good option from developers' point of view. The whole point of this exercise is to save the history. But this can be used for parts that do not require history of course.
svnsync
This is the Subversion remote repository mirroring tool. It allows to mirror a svn and keep it up-todate by syncing the original with the mirror from time to time. svnsync does the magic by replaying the revisions of one repository into another one. And the good news is yes it can be used to break a big repo to several smaller repos by creating mirrors of sub trees. Tests have shown svnrdump, which does things in a very similar way, has better performance. But you may get some nasty errors due to property validations. Take a look at the property validation topic for further details. There is no option to skip validations. Manual fixing of errors is possible, yet not a feasible approach considering the magnitude of the task.
svnadmin dump/load
This command is used to dump the contents of the file system and load it into a new repository. But it cannot dump a sub tree. It's the entire thing or nothing. It can't help us alone, but we can use it with something else called svndumpfilter.
svnrdump dump/load
This is a shining new feature available in SVN 1.7. It proudly announces that it can be used for Remote Repository Data Migration. In simple terms that means even if you're not admin and even if you're not logged into svn server, you can create a dump remotely. It's the cousin of svnadmin dump and a more flexible one. You can dump a sub-tree of the repository through this—something svnadmin dump cannot do. Same property validation errors occur as in svnsync when loading. But the good news is that svnadmin load can skip validations and skipping validation does no harm.
svndumpfilter
Ladies and gentlemen, let me introduce you to the hero of the day! (Or should I say the hero who saved my day).... svndumpfilter! It is a utility for removing history from a Subversion dump file by either excluding or including paths beginning with one or more named prefixes. As per the specs it can operate on any dump file and filter it and give a dump that has only desired content.
There's a small glitch though. We know 2 ways of creating svn dumps; svnadmin dump and svnrdump. As of svn 1.7, svnadmin dump creates a version 2 dump file as the default dump file type. You can specify it to be of version 3 if you want. As the new kid in the block, svnrdump creates only dumps of type version 3. svndumpfilter, being old fashioned, doesn't like to deal with new type of dumps. (It's a known bug) So we must give it a version 2, a dump created by svnadmin dump. Can migrate multiple projects together. It's not possible to use both include and exclude together, but you can always do them one after another. For example include some stuff and get a dump and then filter on the resulting dump to exclude things out of it.
Feasible Solutions
After analyzing all the above, following 2 were identified as the feasible Solutions. Multiple projects can be migrated to the same repository using both options.- Option1 :svnrdump dump & svnadmin load Destination repository need to be in SVN 1.7. (Remember svnrdump is new) Since it's a new feature there can be bugs. (After all we're all developers)
- Option2 :svnadmin dump & svndumpfilter This has been time tested and offer some neat options that are handy.
Revision Numbers
This is something lot of people liked to keep. Bugzilla matched bugs with revision numbers. Release documents contained so many references to revision numbers. svndumpfilter gives some nice options regarding revisions. You can drop empty revisions and renumber the remaining ones. Or you can keep the original ones as it is. So we thought it was easy. It just happened that I had to create some directories for the new repository before I loaded my dump to it. Repository creation was revision 0 and creating these directories was revision 1. And when it started loading, all my revision numbers were getting incremented by one!<<< Started new transaction, based on original revision 1
------- Committed new rev 2 (loaded from original rev 1)
>>> <<< Started new transaction, based on original revision 2 ------- Committed new rev 3 (loaded from original rev 2)
>>>
Well, me and my supervisor wondered, that can be forgiven, it's just one. We can just tell people to look at the x-1 revision. And the suddenly a light bulb flashed! May be, just may be, if we dump from second revision and load it again ???? And yes, to our delight it worked.
svnadmin dump /svn/tempRepo -r 2:HEAD | svnadmin load --bypass-prop-validation /svn/destinationRepo
Option1 :svnrdump dump & svnadmin load
Revision numbers are identical in source and destination
Revision numbers are identical in source and destination
Option2 :svnadmin dump & svndumpfilter
Can keep original revision numbers
If filtering causes any revision to be empty, can remove these revisions from the dump.
Can renumber revisions that remain after filtering. We decided to go with option 2 for the sake of revision numbers.
Can keep original revision numbers
If filtering causes any revision to be empty, can remove these revisions from the dump.
Can renumber revisions that remain after filtering. We decided to go with option 2 for the sake of revision numbers.
Dependency Resolution
Creating a dump sounds as a very easy thing to do, just run the command and wait, isn't it. Yes that can be the case if the developers at your company project teams were enemies and have sworn never to touch the other project's code. But in reality, people think svn is such a cool tool and use it to copy stuff, move stuff from completely random places to another set of completely random places. What they don't know is that svn watches their every move and records them. Say you copy something like /projectA/x/y/fancyCode.java to somewhere in your projectB, you have created a dependency and if you want to filter project B you have to include that copy path too.Handling Binaries
Svn saves stuff in a delta based algorithm. As svn book puts it neatly, To keep the repository small, Subversion uses deltification (or delta-based storage) within the repository itself. Deltification involves encoding the representation of a chunk of data as a collection of differences against some other chunk of data. If the two pieces of data are very similar, this deltification results in storage savings for the deltified chunk—rather than taking up space equal to the size of the original data, it takes up only enough space to say, “I look just like this other piece of data over here, except for the following couple of changes.” The result is that most of the repository data that tends to be bulky—namely, the contents of versioned files—is stored at a much smaller size than the original full-text representation of that data. But things get ugly with binaries. All our jars, docs, pdfs fall into this category. They cannot be diffed. So when your tech writer lady corrects a typo and checks in a huge document, svn simply saves another copy of the document as a new revision. In our repository there was a folder to which they checked in jars. Excluding this folder reduced the repository size by more than 50%. We did things in a smart way and didn't try to add it to a svn again. It was decided to maintain it in a normal directory. Who checked in what, and when didn't matter for these jars which are third party tools. IT folks promised to enforce necessary permissions so that these won't be deleted by anyone. And also there was a folder with documents owned by the tech writers. This part of repository was twice as big as the space took by company's biggest project. We were anyway keeping the old repo as read only and our dear tech writers agreed to kiss the history goodbye for docs folder. Docs were given a fresh start in life as they were simply checked in as new content to the new repos.
Loading multiple projects to the same repository
Specify the parent directory with –parent-dir. Else it will be loaded to the root.
svnadmin load --bypass-prop-validation /svn/destinationRepo --parent-dir A < A.dump
svnadmin load --bypass-prop-validation /svn/destinationRepo --parent-dir B < B.dump
E125005
svnadmin load may fail giving the following error. svnadmin: E125005: Invalid property value found in dumpstream; consider repairing the source or using --bypass-prop-validation while loading. svnadmin: E125005: Cannot accept 'svn:log' property because it is not encoded in UTF-8 Same error is reported as below for svnsync Committed revision 35670. Copied properties for revision 35670. svnsync: At least one property change failed; repository is unchanged svnsync: Error setting property 'log': Could not execute PROPPATCH. This error is due to non-UTF8 encodings are not supported in svn logs. As svn book explains Newer versions of Subversion have grown more strict regarding the format of the values of Subversion's own built-in properties. Of course, properties created with older versions of Subversion wouldn't have benefited from that strictness, and as such might be improperly formatted. Dump streams carry property values as-is, so using Subversion 1.7 to load dump streams created from repositories with ill-formatted property values will, by default, trigger a validation error. There are several workaround for this problem. First, you can manually repair the problematic property values in the source repository and recreate the dump stream. Or, you can manually tweak the dump stream itself to fix those property values. Finally, if you'd rather not deal with the problem right now, use the --bypass-prop-validation option with svnadmin load. One solution is to manually update the logs that are not encoded in UTF 8.
Specify the parent directory with –parent-dir. Else it will be loaded to the root.
svnadmin load --bypass-prop-validation /svn/destinationRepo --parent-dir A < A.dump
svnadmin load --bypass-prop-validation /svn/destinationRepo --parent-dir B < B.dump
Roadblocks You May Encounter
svnadmin load may fail giving the following error. svnadmin: E125005: Invalid property value found in dumpstream; consider repairing the source or using --bypass-prop-validation while loading. svnadmin: E125005: Cannot accept 'svn:log' property because it is not encoded in UTF-8 Same error is reported as below for svnsync Committed revision 35670. Copied properties for revision 35670. svnsync: At least one property change failed; repository is unchanged svnsync: Error setting property 'log': Could not execute PROPPATCH. This error is due to non-UTF8 encodings are not supported in svn logs. As svn book explains Newer versions of Subversion have grown more strict regarding the format of the values of Subversion's own built-in properties. Of course, properties created with older versions of Subversion wouldn't have benefited from that strictness, and as such might be improperly formatted. Dump streams carry property values as-is, so using Subversion 1.7 to load dump streams created from repositories with ill-formatted property values will, by default, trigger a validation error. There are several workaround for this problem. First, you can manually repair the problematic property values in the source repository and recreate the dump stream. Or, you can manually tweak the dump stream itself to fix those property values. Finally, if you'd rather not deal with the problem right now, use the --bypass-prop-validation option with svnadmin load. One solution is to manually update the logs that are not encoded in UTF 8.
svn proplist -v --revprop -r 35670 http://svn.abc.com/project/A | iconv --to-code UTF8//IGNORE -o /tmp/iconv.out
svn propset svn:log --revprop -r 35670 -F /tmp/iconv.out http://svn.abc.com/project/A
svn propset svn:log --revprop -r 35670 -F /tmp/iconv.out http://svn.abc.com/project/A
For my scenario best solution was to by pass the property validations in svnadmin load. What I needed to do was migrate the content as it is to the new repositories. Fixing somebody else's dirty work was not in my specs!
svnadmin load --bypass-prop-validation /svn/destinationRepo < sourceDump.dump
E140001
When tried to use dumpfilter on a dump that was created by svnrdump following error was encountered.
svnrdump dump http://svn.abc.com/project/ | svndumpfilter include /A > A.dump svndumpfilter: E140001: Unsupported dumpfile version: 3
svnadmin dump which creates a dump from a local repository, creates a dump with the default format 'format 2'. svnrdump which creates a dump from a remote repository creates 'format 3' dump files only. svndumpfilter supports only 'format 2' and not 'format 3'
Invalid copy source path
svndumpfilter include /projects/A < fullRepo.dump > A.dump svndumpfilter: Invalid copy source path '/projects/B/xyz' Say you want to move your project A to a different repository. You proudly say that your project is independent and you can survive alone. But then when you put the filter to work to create your dump you get this error. One of your smart developers had seen that project B had just what he wanted and decided to steal their code. He had done a svn copy from /projects/B/xyz to projects/A and now svn says unless you give it that path too it will never create the dump. Svn can be a one tough kid. What you can do is simply give it what it asks for. I call it resolving dependencies. And for a big project their can be quite a number of dependencies. svndumpfilter include /projects/A /projects/B/xyz< fullRepo.dump > A.dump Sometimes you may be forced to add content that can must not be in that repository. In that case you can do a svn delete and delete it from head once the loading is complete.
E160013
Say you create a dump like this
svndumpfilter include /projects/A /projects/B/xyz /projects/C/abc/efg < fullRepo.dump > A.dump
And try to load it
svnadmin load --bypass-prop-validation /svn/destinationRepo < A.dump
And it gives an error, svnadmin: E160013: File not found: transaction '5104-3xs', path 'project/B' This occurs when SVN is unable to figure out certain paths. Manually creating the path fix the issue. What you need to create are the intermediary directories that are there in the include. For example what is there in bold in the following
svndumpfilter include /projects/A /projects/B/xyz /projects/C/abc/efg < fullRepo.dump > A.dump
svnadmin create /svn/destinationRepo
svn mkdir "create folders" \
file:///svn/destinationRepo/projects \
file:///svn/destinationRepo/projects/A \
file:///svn/destinationRepo/projects/C \ file:///svn/destinationRepo/projects/C/abc
svnadmin load --bypass-prop-validation /svn/destinationRepo < A.dump
Do the making of directories in one shot using --parents option.
svn mkdir -m "create folders" --parents \ file:///svn/destinationRepo/projects/A \ file:///svn/destinationRepo/projects/C/abc
This error can also occur due to missing dependencies that didn't cause issues with the filtering. If you get this error for a file, take the svn log for that file and see what has happened in that particular revision the error occurs. For example I got this error due to a folder rename and had to include the earlier path name and create a fresh dump.
1. svn relocate: Relocate the working copy to point to a different repository root URL. This “rewrites” the working copy's administrative metadata to refer to the new repository location. But, it wants to compare the UUID of the repository against what is stored in the working copy. If UUIDs don't match, the working copy relocation is disallowed. We have two ways of keeping the UUID of the source. Please note that this will make both repos to have the same UUID. 1. svnadmin load has following option --force-uuid By default, when loading data into a repository that already contains revisions, svnadmin will ignore the UUID from the dump stream. This option will cause the repository's UUID to be set to the UUID from the stream. 2. svnadmin setuuid — Reset the repository UUID. Reset the repository UUID for the repository located at REPOS_PATH. If NEW_UUID is provided, use that as the new repository UUID; otherwise, generate a brand-new UUID for the repository.
2. svn upgrade — Upgrade the metadata storage format for a working copy. This will be needed for the users to upgrade to svn 1.7 As new versions of Subversion are released, the format used for the working copy metadata changes to accomodate new features or fix bugs. Older versions of Subversion would automatically upgrade working copies to the new format the first time the working copy was used by the new version of the software. Beginning with Subversion 1.7, working copy upgrades must be explicitly performed at the user's request. svn upgrade is the subcommand used to trigger that upgrade process. If you attempt to use Subversion 1.7 on a working copy created with an older version of Subversion, you will see an error.
DUMPDIR=/dumps
SOURCE_REPO=/svn/sourceRepo
svnadmin dump $SOURCE_REPO | svndumpfilter include \
/component \
/docs \
/project/A \
/project/B \
/project/C/applications/journal \ >
$DUMPDIR/A1.dump
svndumpfilter exclude /docs/userguides/custom/ < $DUMPDIR/A1.dump > $DUMPDIR/A.dump
At the destination
DUMPDIR=/dumps
REPO_LOCATION=/svn
rm -rf $REPO_LOCATION/tempRepo
svnadmin create $REPO_LOCATION/tempRepo
svn mkdir -m "create initial folders" --parents \ file://$REPO_LOCATION/tempRepo/project/C/applications
svnadmin load --bypass-prop-validation $REPO_LOCATION/tempRepo < $DUMPDIR/A.dump
rm -rf $REPO_LOCATION/destinationRepo
svnadmin create $REPO_LOCATION/destinationRepo
svnadmin dump $REPO_LOCATION/ tempRepo -r 2:HEAD | svnadmin load --bypass-prop-validation $REPO_LOCATION/destinationRepo
svnadmin load --bypass-prop-validation /svn/destinationRepo < sourceDump.dump
E140001
When tried to use dumpfilter on a dump that was created by svnrdump following error was encountered.
svnrdump dump http://svn.abc.com/project/ | svndumpfilter include /A > A.dump svndumpfilter: E140001: Unsupported dumpfile version: 3
svnadmin dump which creates a dump from a local repository, creates a dump with the default format 'format 2'. svnrdump which creates a dump from a remote repository creates 'format 3' dump files only. svndumpfilter supports only 'format 2' and not 'format 3'
Invalid copy source path
svndumpfilter include /projects/A < fullRepo.dump > A.dump svndumpfilter: Invalid copy source path '/projects/B/xyz' Say you want to move your project A to a different repository. You proudly say that your project is independent and you can survive alone. But then when you put the filter to work to create your dump you get this error. One of your smart developers had seen that project B had just what he wanted and decided to steal their code. He had done a svn copy from /projects/B/xyz to projects/A and now svn says unless you give it that path too it will never create the dump. Svn can be a one tough kid. What you can do is simply give it what it asks for. I call it resolving dependencies. And for a big project their can be quite a number of dependencies. svndumpfilter include /projects/A /projects/B/xyz< fullRepo.dump > A.dump Sometimes you may be forced to add content that can must not be in that repository. In that case you can do a svn delete and delete it from head once the loading is complete.
E160013
Say you create a dump like this
svndumpfilter include /projects/A /projects/B/xyz /projects/C/abc/efg < fullRepo.dump > A.dump
And try to load it
svnadmin load --bypass-prop-validation /svn/destinationRepo < A.dump
And it gives an error, svnadmin: E160013: File not found: transaction '5104-3xs', path 'project/B' This occurs when SVN is unable to figure out certain paths. Manually creating the path fix the issue. What you need to create are the intermediary directories that are there in the include. For example what is there in bold in the following
svndumpfilter include /projects/A /projects/B/xyz /projects/C/abc/efg < fullRepo.dump > A.dump
svnadmin create /svn/destinationRepo
svn mkdir "create folders" \
file:///svn/destinationRepo/projects \
file:///svn/destinationRepo/projects/A \
file:///svn/destinationRepo/projects/C \ file:///svn/destinationRepo/projects/C/abc
svnadmin load --bypass-prop-validation /svn/destinationRepo < A.dump
Do the making of directories in one shot using --parents option.
svn mkdir -m "create folders" --parents \ file:///svn/destinationRepo/projects/A \ file:///svn/destinationRepo/projects/C/abc
This error can also occur due to missing dependencies that didn't cause issues with the filtering. If you get this error for a file, take the svn log for that file and see what has happened in that particular revision the error occurs. For example I got this error due to a folder rename and had to include the earlier path name and create a fresh dump.
After the migration
Once the migration is complete compare the svn logs of source and destination. Getting the logs in xml formats is good if the source and destination are in two different svn versions, since with version the format of logs may differ. A merge too can be used to compare the two logs in xml format. Viewsvn can also be used to verify the contents after migration. Once the migration is done, users' working copies have to be pointed to the new repositories. What we did was simply ask the users to get fresh check outs. Following can be useful for those who don't like to do that.1. svn relocate: Relocate the working copy to point to a different repository root URL. This “rewrites” the working copy's administrative metadata to refer to the new repository location. But, it wants to compare the UUID of the repository against what is stored in the working copy. If UUIDs don't match, the working copy relocation is disallowed. We have two ways of keeping the UUID of the source. Please note that this will make both repos to have the same UUID. 1. svnadmin load has following option --force-uuid By default, when loading data into a repository that already contains revisions, svnadmin will ignore the UUID from the dump stream. This option will cause the repository's UUID to be set to the UUID from the stream. 2. svnadmin setuuid — Reset the repository UUID. Reset the repository UUID for the repository located at REPOS_PATH. If NEW_UUID is provided, use that as the new repository UUID; otherwise, generate a brand-new UUID for the repository.
2. svn upgrade — Upgrade the metadata storage format for a working copy. This will be needed for the users to upgrade to svn 1.7 As new versions of Subversion are released, the format used for the working copy metadata changes to accomodate new features or fix bugs. Older versions of Subversion would automatically upgrade working copies to the new format the first time the working copy was used by the new version of the software. Beginning with Subversion 1.7, working copy upgrades must be explicitly performed at the user's request. svn upgrade is the subcommand used to trigger that upgrade process. If you attempt to use Subversion 1.7 on a working copy created with an older version of Subversion, you will see an error.
Summarized Commands
At the sourceDUMPDIR=/dumps
SOURCE_REPO=/svn/sourceRepo
svnadmin dump $SOURCE_REPO | svndumpfilter include \
/component \
/docs \
/project/A \
/project/B \
/project/C/applications/journal \ >
$DUMPDIR/A1.dump
svndumpfilter exclude /docs/userguides/custom/ < $DUMPDIR/A1.dump > $DUMPDIR/A.dump
At the destination
DUMPDIR=/dumps
REPO_LOCATION=/svn
rm -rf $REPO_LOCATION/tempRepo
svnadmin create $REPO_LOCATION/tempRepo
svn mkdir -m "create initial folders" --parents \ file://$REPO_LOCATION/tempRepo/project/C/applications
svnadmin load --bypass-prop-validation $REPO_LOCATION/tempRepo < $DUMPDIR/A.dump
rm -rf $REPO_LOCATION/destinationRepo
svnadmin create $REPO_LOCATION/destinationRepo
svnadmin dump $REPO_LOCATION/ tempRepo -r 2:HEAD | svnadmin load --bypass-prop-validation $REPO_LOCATION/destinationRepo
svn delete -m "delete unwanted content" file://$REPO_LOCATION/destinationRepo/project/C
Tuesday, April 24, 2012



Thursday, April 19, 2012

Thursday, March 29, 2012



Friday, March 23, 2012
I love my JAVA
I've been a book addict since childhood, I read everything! From pieces of newspaper to classics to fiction to whatever that was printed in black and white.. or so I thought since I've not laid my hand on computer books at that time...
I've been a software engineer for 5 years! Yet it was only last week I finished reading the first computer/software related book, that I can claim I read from beginning to end.
Can there be anything duller than reading a complete software book? As per my opinion the sole purpose of their existence is for reference, and whoever is using books for reference nowadays is plain stupid since Googling is much faster than flipping through pages!
I was proved wrong by 2 wonderful people and I'm so happy they did it. Kathy Sierra Bates and Bert Bates who wrote SCJP SUN CERTIFIED PROGRAMMER FOR JAVA 6 have made it so wonderfully readable, I couldn't stop reading it!!! It burns the concepts in your head and the authors don't allow you to comfortably skip stuff... They give several examples and illustrate in various angles making it so very clear and making it difficult not to understand!

As I said I've been a java developer for years, but this book for beginners really did teach me a lot that I didn't know before. Especially since I was a self-taught developer my knowledge wasn't organized and had a lot of gaps.
I've pinched myself really hard several times for not doing this few years back! It's THE guide for SCJP (or OCPJP as it's called now), but even without the exam it's a must read for a Java person.
I didn't really have to pay for it since I downloaded the softcopy and studied it.(It’s freely available in internet) Trust me, learning Java is so fun with this book..
Sunday, March 11, 2012
Configure Outlook for Your Gmail
It's my first work from home day!
I knew I was addicted to Microsoft Outlook, all it's friendly features and professional feel. Since I don't have my office mail account, I was wondering if I can access my gmail account from my laptop's outlook.
In two minutes Google searched the answer for me and now I'm happily accessing my gmail from Outlook :)
I thought it'd be easier if there was a screenshot guide rather than a textual guides I found. So I took screen shots of what I did.
Have fun!





Click on More Settings button...


Click ok in above and click next in the form beneath. Connections will be tested and if it succeeds it will go to the finish screen,


Subscribe to:
Posts (Atom)